Technology
We are Data People


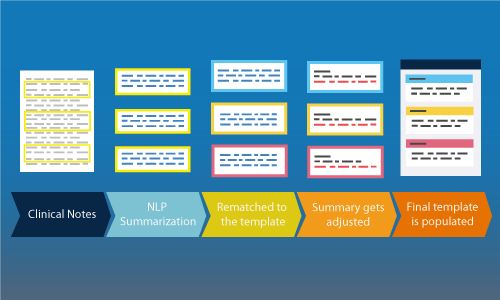
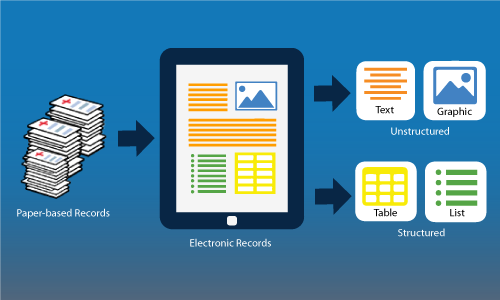
Apurba leverages the power of Natural Language Processing (NLP) to understand textual and tabular data to derive actionable intelligence.

Apurba has developed a framework that we call Big-Data-in-a-Box which can be adapted to various applications and platforms with relative ease.

Apurba exploits the power of Machine Learning to model your complex data, solve your big puzzles and answer your tough questions.




Years of Experience
Satisfied Clients
Completed Projects
Patents